JDK1.7ConcurrentHashMap源码解读
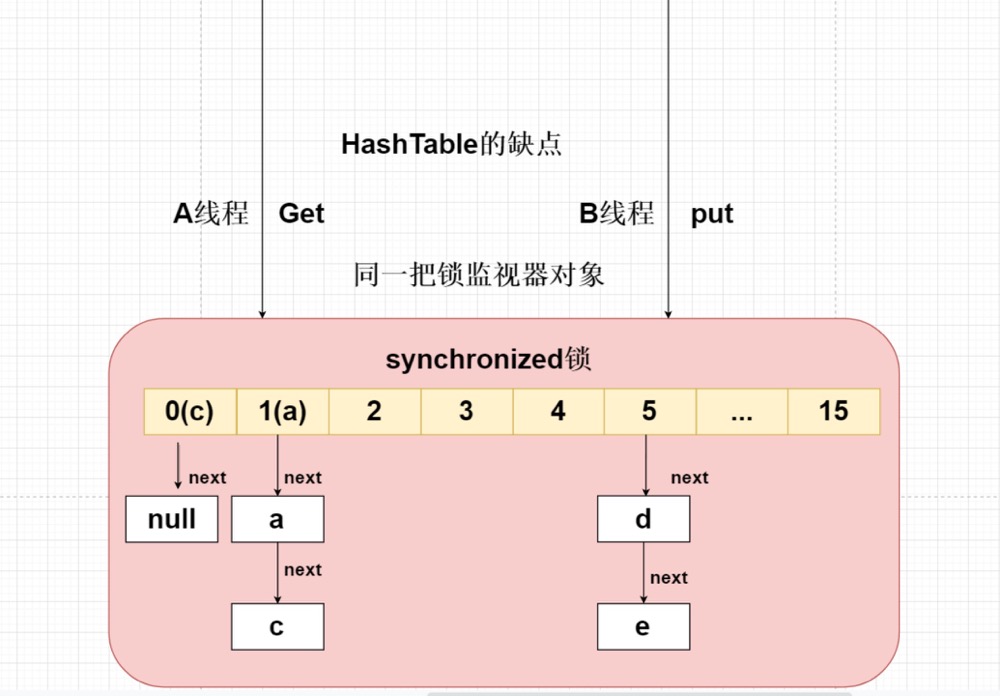
使用传统HashTable保证线程问题,是采用synchronized锁将整个HashTable中的数组锁住,
在多个线程中只允许一个线程访问Put或者Get,效率非常低,但是能够保证线程安全问题。
Jdk官方不推荐在多线程的情况下使用HashTable或者HashMap,建议使用ConcurrentHashMap分段HashMap。
效率非常高。
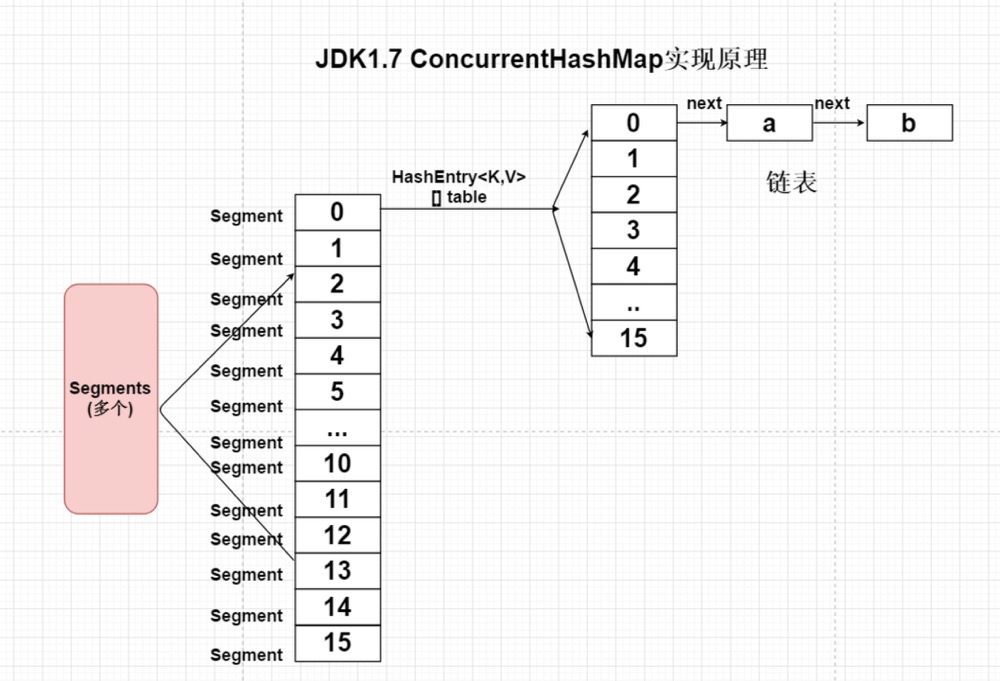
ConcurrentHashMap将一个大的HashMap集合拆分成n多个不同的小的HashTable(Segment),默认的情况下是分成16个不同的
Segment。每个Segment中都有自己独立的HashEntry<K,V>[] table;
核心参数:
initialCapacity —16 初始化
loadFactor HashEntry<K,V>[] table; 加载因子0.75
concurrencyLevel 并发级别 默认是16
cas与乐观锁机制原理(简单)
一直卡死,消耗cpu资源,一直重试。
hashtable缺点
底层使用synchronized锁实现的,但是将整个数组都给锁住了。
1.7ConcurrentHashMap
将一个大的ConcurrentHashMap集合拆分成n多个不同的hashtable,在每个小的hashtable中都有自己的table【】
package com.gtf.xc;
import java.util.HashMap;
public class MyConcurrentHashMap
<K, V> {
/**
* segments
*/
private HashMap<K,V>[] segments;
public MyConcurrentHashMap() {
segments=new HashMap[16];
//注意是懒加载
}
public void put(K key, V value) {
//第一次计算key,计算key存放在哪一个hashtable
int segmentsIndex =key.hashCode()& (segments.length - 1);
HashMap<K, V> segment = segments[segmentsIndex];
//segment == null
if (segment == null) {
segment=new HashMap<>();
}
segment.put(key,value);
segments[segmentsIndex]=segment;
}
public V get(K key) {
int segmentsIndex =key.hashCode()& (segments.length - 1);
HashMap<K, V> segment = segments[segmentsIndex];
if (segment != null) {
return segment.get(key);
}
return null;
}
public static void main(String[] args) {
MyConcurrentHashMap<Object, Object> objectObjectMyConcurrentHashMap = new MyConcurrentHashMap<>();
for (int i = 0; i < 10; i++){
objectObjectMyConcurrentHashMap.put(i,i);
}
for (int i = 0; i < 10; i++) {
objectObjectMyConcurrentHashMap.get(i);
System.out.println( objectObjectMyConcurrentHashMap.get(i));
}
}
}
没有获取到锁的线程
- 自旋 缓存当前对应冲突链表
- 每次检查 当前缓存链表头节点是否发生变化
- 如果发生变化的情况下 缓存最新
- 自旋的次数最多为64
实现原理
- 由多个不同的sement对象组成
- 使用 luck锁+cas
- unsafe 直接查询主内存最新的数据
- 使用cas做修改
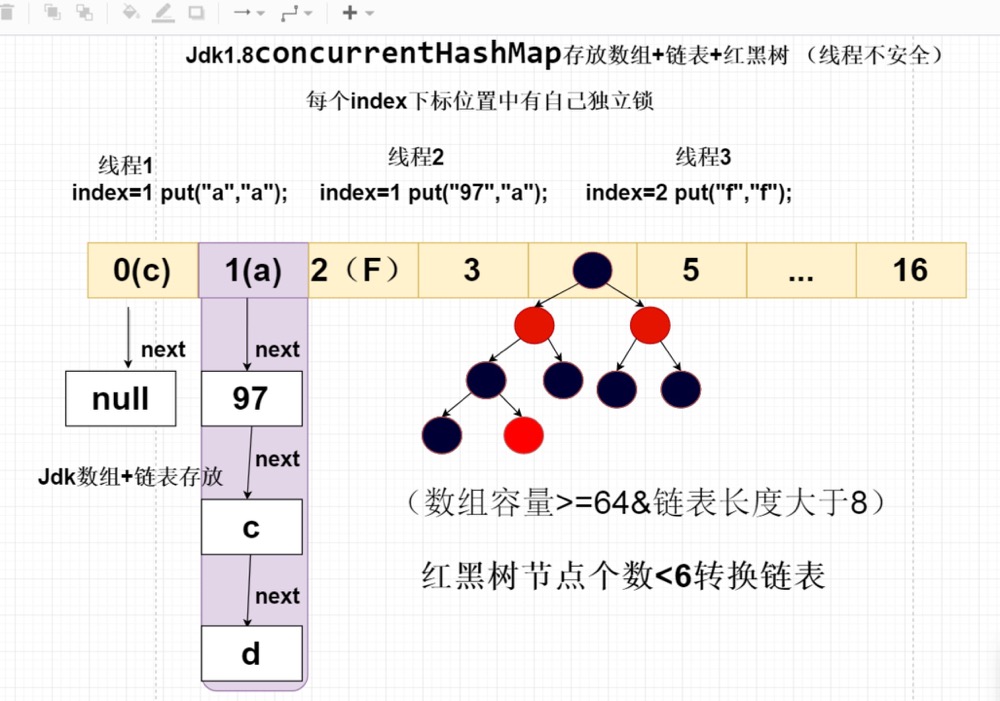
JDK1.8ConcurrentHashMap
ConcurrentHashMap1.8的取出取消segment分段设计,采用对CAS + synchronized保证并发线程安全问题,将锁的粒度拆分到每个index
下标位置,实现的效率与ConcurrentHashMap1.7相同。